Базы данных: введение, часть вторая
Илья Тетерин
2012-10-01
(use arrow keys or PgUp/PgDown to move slides)
Илья Тетерин
2012-10-01
(use arrow keys or PgUp/PgDown to move slides)
Своя база данных на Java (Ruby/Python/etc)
Из чего состоит получившаяся база?
Хранить данные в памяти
ArrayList
get o(1), insert o(n), del o(n), append o(1)/o(n)
LinkedList
get o(n), insert o(n), del o(n), append o(1)
Map / ассоциативный массив
public void add(final Record); public void put(final K key, final V value); public byte[] get(String key); public Record get(Key key);
А как хранить внутри? Запись vs Строка vs byte[]
Кстати: Можно использовать готовую от языка, можно написать свою.
Понять что хочет пользователь, обработать данные, понять команду, передать в коллекцию.
Трансформация внешнего API к внутреннему и обратно
System.out.println("create <key> <name> <phone> - add record to db");
System.out.println("delete - delete record from db");
System.out.println("retrieve - get record from db");
System.out.println("update - update record in db");
System.out.println("commit - save db");
System.out.println("q - exit");
if (arr[0].equals("exit")) {
System.exit(0);
}
if (arr[0].equals("create")) {
this.create(arr[1], arr[2], Integer.parseInt(arr[3]));
return;
}
Добавить
Получить
Обновить
Удалить
C R U D
MyDatabase.saveRecord(Record r)
vs
arr[0].equals("create")
Задачи:
Возвращать данные из нашей базы
Принимать команды от пользователя и отправлять в базу
Вызывать парсер
Обеспечивает доступ пользователя к базе
Варианты: консоль, командная строка, http, socket
Serialize / Маршализация
Коллекция в памяти - сложная, нелинейная структура (размер, указатели, данные в произвольных местах памяти)
Внешняя память, передача по сети - линейны, нужно преобразовать граф в последовательность и обратно
Устройство HashMap в Java
... аналогично записной книжке ...
Набор бакетов, каждый бакет - значение хеша + список пар (ключ, значение).
При укладке берем hash от ключа, определяем бакет, перебираем последовательно элементы списка
Если найден ключ - обновляем значение
Если дошли до конца и не нашли, добавляем в конец списка
Событие рехеширования и перекладки по бакетам
константный hash у ключей - плохо, всегда один бакет и o(n)
Практическая полезность такой базы?
Ценность базы определяется ценностью данных, находящихся в ней.
Ценность данных - сравнительная стоимость их получения из базы по сравнению со стоимостью получения другим путем.
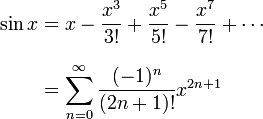
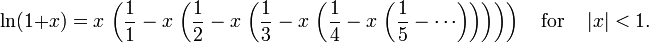
Таблицы математических функций - wiki:Mathematical table
Первые таблицы тригонометрических функций - Гиппарх - 190-120 BC - не сохранились
Птоломей - 90-168 г.н.э. (Ptolemy's table of chords) - дожили до наших дней
Во время войны - активно считались таблицы для артиллерии ...
Таблицы Брадиса - ключ - аргумент (угол или число) с некоей точностью, значение - значение функции от этого числа.
синусы, косинусы, тангенсы, котангенсы, логарифмы, степени 10, площадь круга етс ...
Нужен логарифм от 1.257 по основанию 10
| N | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 1.23 | .089905 | .090258 | .090611 | .090963 | .091315 | .091667 | .092018 | .092370 |
| 1.24 | .093422 | .093772 | .094122 | .094471 | .094820 | .095169 | .095518 | .095866 |
| 1.25 | .096910 | .097257 | .097604 | .097951 | .098298 | .098644 | .098990 | .099335 |
| 1.26 | .100371 | .100715 | .101059 | .101403 | .101747 | .102091 | .102434 | .102777 |
| 1.27 | .103804 | .104146 | .104487 | .104828 | .105169 | .105510 | .105851 | .106191 |
Что быстрее: посчитать или найти в таблице?
Creating tables stored in random access memory is a common code optimization technique in computer programming, where the use of such tables speeds up calculations in those cases where a table lookup is faster than the corresponding calculations (particularly if the computer in question doesn't have a hardware implementation of the calculations). In essence, one trades computing speed for the computer memory space required to store the tables.
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns Main memory reference 100 ns 20x L2 / 200x L1 cache Compress 1K bytes with Zippy 3,000 ns Send 1K bytes over 1 Gbps network 10,000 ns 0.01 ms Read 4K randomly from SSD* 150,000 ns 0.15 ms Read 1 MB sequentially from memory 250,000 ns 0.25 ms Round trip within same datacenter 500,000 ns 0.5 ms Read 1 MB sequentially from SSD* 1,000,000 ns 1 ms 4X memory Disk seek 10,000,000 ns 10 ms 20x datacenter roundtrip Read 1 MB sequentially from disk 20,000,000 ns 20 ms 80x memory, 20X SSD Send packet CA->Netherlands->CA 150,000,000 ns 150 ms
Регистры процессора - ключи имена регистров, значения - целое число, лежащее в регистре.
in-process - обычный Map в памяти вашего процесса
in-memory - Map, живущий вне вашего процесса и доступный по какому-то API снаружи
on-disk - Map, способный пережить отключение электричества (persistent memory)
доступный по сети - несколько компьютеров могут обращаться к нему по сети
Смотрите затраты - бенефиты ...
in-memory:
- Memcached (wiki 2003)
- Redis (redis.io) - очень модный сейчас Key-Value
on-disk:
- dbm (wiki) - 1979-ый год, неотъемлимая часть *NIX
- Berkeley DB (wiki) - 1996, сейчас часть Oracle Corp.
- Tokio Cabinet / Kyoto Cabinet
- LevelDB by Google - 2011-ый год
... на страничке http://en.wikipedia.org/wiki/Dbm есть неполный список ...
... а можете свой написать ... :)
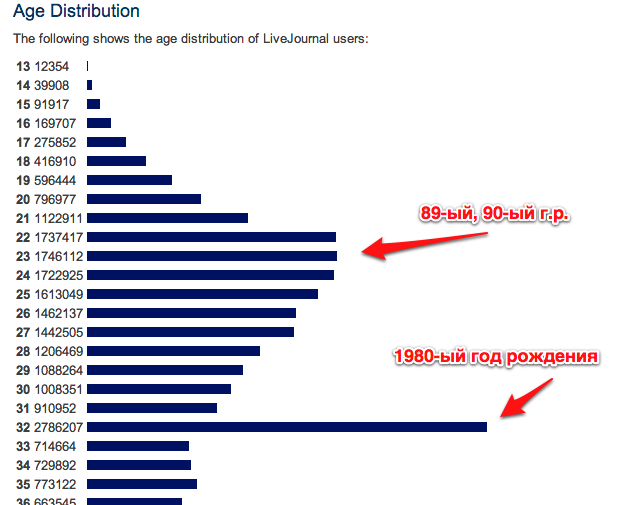
Bradley Joseph "Brad" Fitzpatrick ... родился в 1980-ом
15 апреля 1999-го года - запустил сервис "дабы друзья по ВУЗу знали чем занимаюсь" ...
История LJ по годам: wiki: LiveJournal timeline
November 4, 2001 - первый full-time сотрудник avva
April 11, 2003 - 1 миллион аккаунтов
May 22, 2003 - разработан Memcached
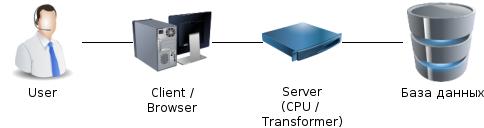
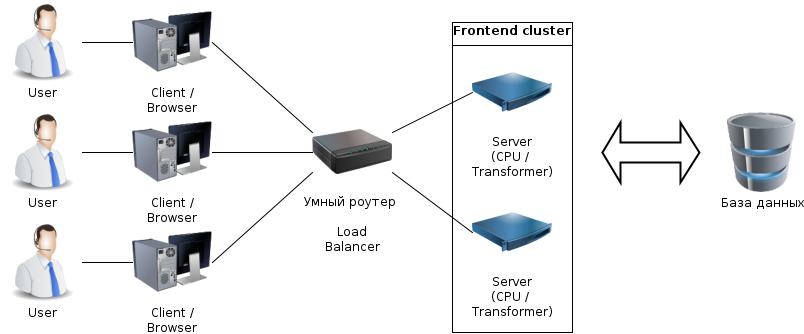
Зачем нужен сервер?
Формат данных прямо из базы непонятен клиенту.
На сервере CPU нагрузка - обсчитать что-то, проверить правила етс.
База данных "чужая" и неизменная, а на сервере можно запрограммировать что хотим.
Один сервер не справляется:
- поставим умный router (balancer)
- поставим несколько серверов за balancer-ом
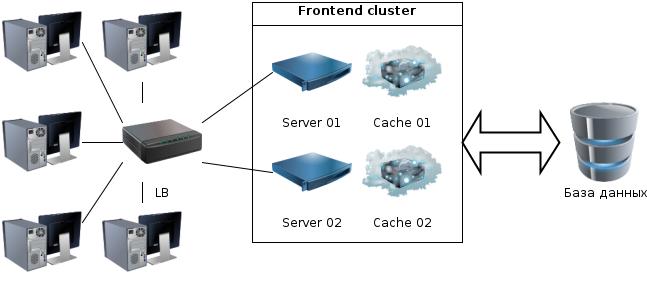
Зачем считать каждый раз, если можно в кеш (Map в памяти) положить?
result process(request) {
value = cacher.get(request);
if(value > 0) return value;
value = renderPage(request);
cache.put(request,value);
return value;
}
Кстати: очень сильно уменьшилась нагрузка на базу.
В каждом из них встречаются одинаковые значения
Одинаковые = много раз посчитанные = нагрузка на CPU
У него ограничен размер = мало значений можно положить
Значения считаются один раз, вне зависмости от количества серверов
Уникальны на уровне кластера - нет повторов - больше можно хранить
Общий размер = сумме каждого per server кеша
Поставим доступные по сети KV storages: kv01, kv02, kv03
Напишем библиотечку cacher
val servers[] = ['kv01','kv02','kv03'];
cacher {
put (key,value) {
n = hash(key) mod servers.length;
remotePut(n,key,value);
}
get (key) {
n = hash(key) mod servers.length;
return remoteGet(n, key);
}
}
Надо больше?
Поставь kv01 .. kv32 и на каждом по 4Mb памяти = 128Mb общей памяти.
Памяти все равно не хватает?
Выпихивай "старые" данные (LRU / Least Recently Used).
"Залипают" старые данные?
Добавь поддержу TTL (time to live), e.g. хранить данные в cache 30 секунд.
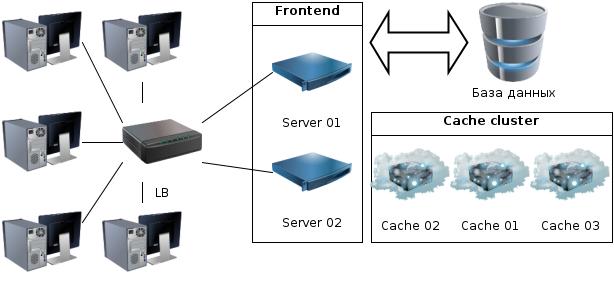
Balancer - выбирает на какой сервер идти (round-robin / близость / нагруженность) Server - через клиентскую библиотеку выбирает ноду в Cache и хранит там посчитанное Cache - контролирует свою память и выкидывает самые старые (LRU) или устаревшие (TTL) данные
Memcached is an in-memory key-value store for small chunks of arbitrary data (strings, objects) from results of database calls, API calls, or page rendering.
Memcached was originally developed by Brad Fitzpatrick for LiveJournal in 2003.
Contributed: 80+ человек
Больше информации: yandex:memcached
Где используется?
- YouTube, Reddit, Zynga, Facebook, Orange, Twitter, Wikipedia.
- Heroku (Couchbase-managed memcached add-on) service
- Google App Engine, AppScale, Windows Azure and Amazon Web Services - own memcached service API implementation.
NB: невозможно из серверов получить список всех ключей - это feature.
Список серверов в клиенте - добавить новый сервер = перезапусти всех клиентов.
Ответ: вынеси клиентскую библиотеку в отдельный сервис-прокси поверх memcached.
Список серверов == hash функция - добавил новый сервер - не найдешь старые данные.
Ответ:- устойчивые функции хеширования.
Перезапуск кластера - всё только в памяти = пустой cache = все идут в базу, база "ложится".
Ответ 1: "разогревай" cache до того, как запускать пользователей.
Ответ 2: запоминай состояние на диск = "persistent" KV storage на диске (redis/leveldb/tokyo).
Установить:
google:install memcached / Tug's Blog: Installing Memcached on Mac OS X and using it in Java.
curl -O http://www.monkey.org/~provos/libevent-1.4.14-stable.tar.gz tar xzvf libevent-1.4.14-stable.tar.gz cd libevent-1.4.14-stable ./configure && make && make verify && sudo make install curl -O http://memcached.googlecode.com/files/memcached-1.4.10.tar.gz tar xzvf memcached-1.4.10.tar.gz cd memcached-1.4.10 ./configure && make && make test && sudo make install --- Запуск: /usr/local/bin/memcached -d -p 11211 --- Использование через telnet pulser$ telnet localhost 11211 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. set user:9091:city 0 30 6 -- здесь: ключ флаги TTL str.length Moscow STORED ^] telnet> quit Connection closed.
import java.io.*;
import java.util.logging.*;
import net.spy.memcached.AddrUtil; // spymemcached library
import net.spy.memcached.MemcachedClient;
public class SpyTest {
public static void main(String[] args) {
try {
System.out.print("Enter the new key : ");
final BufferedReader reader = new BufferedReader(
new InputStreamReader(System.in));
final String key = reader.readLine();
System.out.print("Enter the new value : ");
final String value = reader.readLine();
final MemcachedClient cache = new MemcachedClient(
AddrUtil.getAddresses("127.0.0.1:11211"));
// read the object from memory
System.out.println("Get Object before set :"+ cache.get(key) );
// set a new object
cache.set(key, 0, value );
System.out.println("Get Object after set :"+ cache.get(key) );
} catch (IOException ex) {
Logger.getLogger(SpyTest.class.getName()).log(Level.SEVERE, null, ex);
System.exit(0);
}
System.exit(0);
}
}
Делаем маленькое приложение внутри которого функция хеширования
с одной стороны запросы клиентов на один адрес, на один порт
с другой стороны коннекты ко всем шардам базы данных
внутри только функция шардирования и список шардов (данных нет!)
Чем плохо?
- доп. накладные расходы - на один хост дальше сетевой путь = +2 сетевые задержки,
- большое количество траффика через одну точку - может захлебнуться сеть,
- Single Point Of Failure - завалился раутер = совсем никаких данных не получат все клиенты
Главное требование - равномерность распределения значений по бакетам
values = [0,1,2,4,5,6,8,9];
-- сделали функцию, разложили по ведеркам
f = x % 2;
buckets = { 0 -> 0,2,4,6,8 }, {1 -> 1,5,9 }
-- что-то неравномерно получилось, память напрягает, хочу ровнее
-- поменяюю чуточку функцию
f = x % 3;
buckets = { 0 -> 0, 6, 9} { 1 -> 1,4 } { 2 -> 2, 5, 8 }
-- переезды: 3 "желанных" - 2, 5, 8 и 2 "ну зачем" 4, 9
-- причем 9 полезло "в загруженный" бакет ...
А проблема ли это?
Foursquare: So, that was a bummer., Oct 05, 2010 ...
... one of these shards was performing poorly because a disproportionate share of check-ins ... we introduced a new shard, intending to move some of the data from the overloaded shard to this new one ... For reasons that are not entirely clear to us right now, though, the addition of this shard caused the entire site to go down ...
f = первая цифра телефона делаем 10 бакетов, раскладываем выясняется, что у нас много юр. лиц получаем, что бакеты 3 и 7 переполнены, а остальные недогружены аналогичная ситуация: - первая буква фамилии - район города - страна - класс персонажей - етс.
Главное требование - равномерность распределения по бакетам реальных данных ...
... а данные распределены не равномерно - даже при хорошей функции - количество в бакетах будет разное
... нужны динамические адаптивны функции хеширования, подстраиваующиеся к данным ...
bucket_end = [ 100, 200, 300, 400 ]
-- "0..99, 100..199, 200..299, 300..399"
int bucket ( key : int ) {
h = key % max ( bucket_end[] )
for ( i = 0; i < bucket_end.length; i++ ) {
if ( h < bucket_end[i] ) {
return i;
}
}
return 0;
}
-- у нас переполняется бакет 200-299 ...
-- добавим и подвигаем ведерки - "200-274, 275-324, 325-399"
bucket_end = [ 100, 200, 275, 325, 400 ]
public class A {
int hash(int[] ends, int key) {
int max = 0;
for (int i : ends)
if ( i > max ) max = i; // ищем верхнюю границу
int h = key % max; // хешируем по границе
for (int i = 0; i < ends.length; i++) {
if ( h < ends [i] )
return i; // ищем бакет, в который попадает hash
}
return 0; } // не нашли? - кладем в первый бакет
// раскладываем по бакетам и красиво выводим на экран что получилось
void dump(int[] ends, int[] probes){
// tree map - ключи отсортированы по возрастанию - первым будет бакет 0 ...
Map<Integer,List<Integer>> m = new TreeMap<Integer,List<Integer>>();
for (int key: probes) {
int h = hash(ends, key);
if ( m.get(h) == null ) m.put(h, new ArrayList<Integer>());
m.get(h).add(key);
}
System.out.println(m);
}
static int[] ends1 = new int[]{ 100, 200, 300, 400};
static int[] ends2 = new int[]{ 90, 200, 275, 310, 400};
public static void main(String[] args) throws Exception {
int[] probes = new int[] { 7, 67, 127, 187, 215, 260, 285,
290, 299, 312, 315, 325, 370, 490, 800, 825 };
new A().dump(ends1, probes);
new A().dump(ends2, probes);
}
}
-- первый запуск - "100, 200, 300, 400"
{0=[7, 67, 490, 800, 825], 1=[127, 187],
2=[215, 260, 285, 290, 299], 3=[312, 315, 325, 370]}
-- размеры 5, 2, 5, 4
-- второй - "90, 200, 275, 310, 400"
{0=[7, 67, 800, 825], 1=[127, 187, 490],
2=[215, 260], 3=[285, 290, 299], 4=[312, 315, 325, 370]}
-- размеры 4, 3, 2, 3, 4
В реальном мире - кольцо может быть длиной не в 400 "ячеек", а в 2^160 ..
И в таком "кольце" вы можете расположить очень большое количество нод.
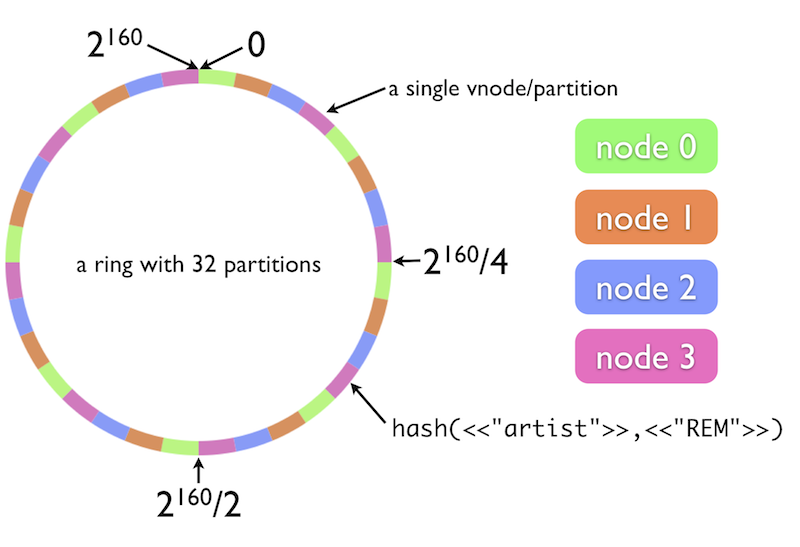
f = h1(h2(h3(h4(h5(key))))); ...
f = md5sum(key.hashCode()) % num_buckets ...
Делаем двух уровневую структуру хранения:
- 20 нод, внутри каждой ноды 60 бакетов
а) balancer внутри которого h1 = k % 20
b) на входе в ноду h2 = k % 60
... запускаем систему и смотрим статистику нагрузки ... почему-то на ноде #0 данные только в бакетах 0, 20, 40 ... ... и *нет* данных во всех других бакетах ... в ноде #1 - 1, 21, 41 ... и все остальные пусты
Почему?
Ответ: ой, используем зависимые функции ...
DDI: Как я укачал 250 млн страниц за 40 часов и $580
wiki: K-independent hashing
wiki: Compime / Взаимно простые числа - когда единственный общий множитель единица
http://redis.io/ / wikipedia:Redis / yandex:Redis
http://redis.io/commands - 144 (было 124 в 2011-ом) разных комманды ( o_O )
The Little Redis Book. Есть перевод на русский.
БОльше чем key-value ...
Структуры данных:
- строки (strlen, append, getrange) - числа - атомарные incr / decr / incrby - hashes - hset / hmset (users:goku age 40 weight 85) / hget users:goku weight - lists - rpush / ltrim - sets - sorted sets - группировка команд в одну
NB: Redis однопоточный внутри - меньше lock / synchronize = быстрее.
Делаем копию базы, налету, средствами самой базы.
Либо каждую полученную команду изменения мастера отправляем на slave - log replication
Может быть синхронным (клиенту не говорим ОК пока slave не сказал "всё записано, босс")
Может быть асинхронным (master - OK клиенту, а slave этого и не увидел (еще)).
Либо раз в какой-то период делаем snapshot базы и отправляем на slave
При snapshot - запаздывание может быть больше (но с этим можно жить - см. Таблицы Брадиса и их переиздание раз в N лет :) ).
А балансировка нагрузки - запись через 1 master, чтение через 5 slaves
"Надежность" - master вырубился, выбираем одного из живых slave и апгрейдим до master, начинаем писать туда.
Восстановившись старый мастер становится slave, либо "нагоняет" временного мастера по логам и возвращается на место master
Запаздывание slave относительно мастер в случае асинхронной репликации
Невозможность принять update, когда синхронная репликация на slave, а slave недоступен
Если быстро пишем, то запаздывание может накапливаться и "слейв не успевает"
Дополнительная нагрузка на сеть - данные копируются на slave-ов. (Можно делать деревья из slave, но там задержки еще больше)
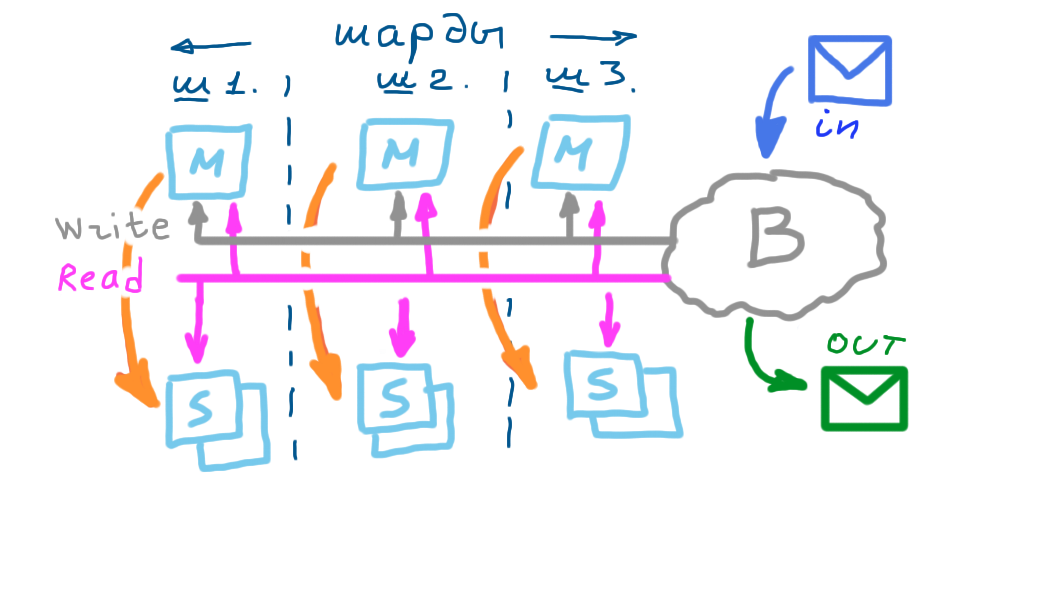
У вас уже есть работающая "нода" - отдельно стоящий key-value storage
Надо к нему добавить:
- master-slave репликацию ( прокидывание команд add / update / del на slave )
- роутинг ( у нас есть master и slave - на мастер add/update/del, на slave - retrieve)
- раз есть роутинг - добавим шардирование - часть ключей на одних нодах, часть на других
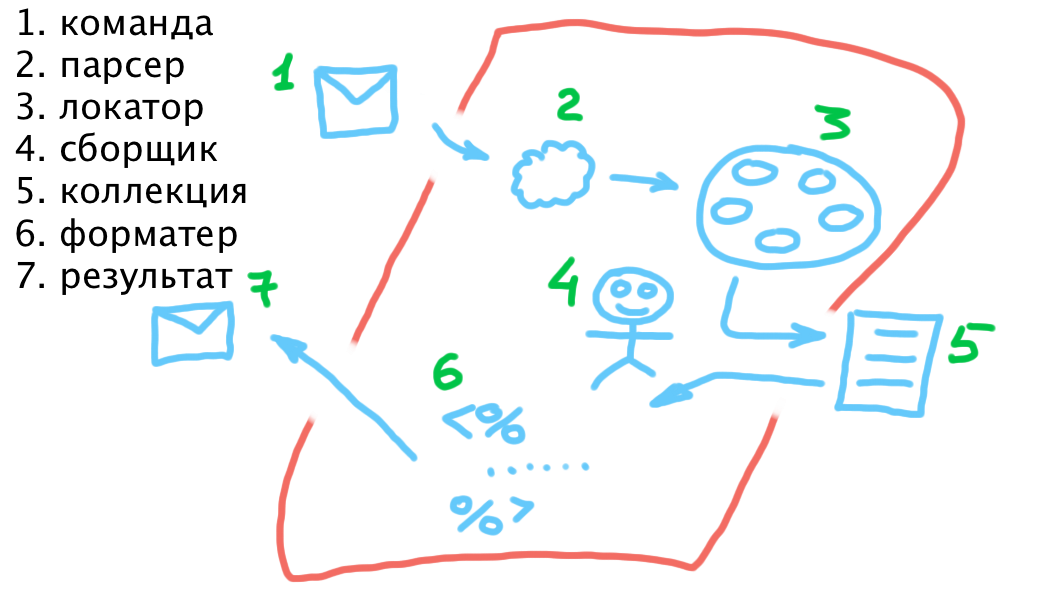
http://voituk.kiev.ua/2008/12/22/simple-reliable-java-http-server/
import java.io.IOException;
import java.io.PrintWriter;
import java.net.InetSocketAddress;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpHandler;
import com.sun.net.httpserver.HttpServer;
public class HttpServerEx implements HttpHandler {
public static void main(String[] args) throws IOException {
HttpServer server = HttpServer.create(new InetSocketAddress(80), 10);
server.createContext("/", new HttpServerEx());
server.start();
System.out.println("Server started\nPress any key to stop...");
System.in.read();
server.stop(0);
System.out.println("Server stoped");
}
public void handle(HttpExchange exc) throws IOException {
exc.sendResponseHeaders(200, 0);
PrintWriter out = new PrintWriter(exc.getResponseBody());
out.println( "Hello moto!" );
out.close();
exc.close();
}
}Apache HttpClient (http://hc.apache.org/httpcomponents-client-ga/index.html)
Quick Start
HttpClient client = new DefaultHttpClient();
HttpGet request = new HttpGet("http://www.vogella.com");
HttpResponse response = client.execute(request);
// Get the response
BufferedReader rd = new BufferedReader
(new InputStreamReader(response.getEntity().getContent()));
String line = "";
while ((line = rd.readLine()) != null) {
System.out.println(line);
}
http://json.org/ / wikipedia:JSON / yandex:JSON
{"person": {
"id": "75685",
"fio": "Илья Тетерин",
"контакты": {
"twitter": "ya_pulser",
"url": "http://fluffypulser.ru",
"email": "ya.pulser@gmail.com"
} } }Есть еще YAML [YAML Ain’t Markup Language] (specs). Описание на wiki: YAML.
receipt: Oz-Ware Purchase Invoice
date: 2007-08-06
customer:
given: Dorothy
family: Gale
a) отдельный архив исходников
b) отдельный архив собранных .jar с .sh для запуска и раскладкой по каталогам (shard01/master, shard01/slave etc.)
c) подробное описание раскладки по процессам/портам + инструкция по запуску (что в каком порядке поднимать)
d) в архив из п.б) включен тестовый набор данных, заливаемых через
cat data.txt | command-line-client.sh
e) клиент (Firefox http://localhost:8003/? :)), дабы подсоединиться к конкретной node и посмотреть, какие в ней данные
Поднимаем:
- router
- shard 01 (master + slave)
- shard 02 (master + slave)
Заливаем данные (три записи).
Проверяем, куда данные попали (shard / master / slave).
Отрываем master - смотрим, что данные можно прочитать, но нельзя записать через клиент
Возвращаем мастера, обновляем данные - смотрим что все ок через клиента
Отрываем целиком shard - и проверяем, что данные из клиента и не прочитать и не записать
Пример на json
cat /tmp/dbroot/config.json
{
"router" : { "addr":"localhost:8200" },
"shard01": {
"master" : {"addr":"localhost:8201", "path":"/tmp/dbroot/master01.data"},
"slave" : {"addr":"localhost:8202", "path":"/tmp/dbroot/slave01.data"}
},
"shard02": {
"master" : {"addr":"localhost:8301", "path":"/tmp/dbroot/master02.data"},
"slave" : {"addr":"localhost:8302", "path":"/tmp/dbroot/slave02.data"}
}
}
Но можно на xml, на txt, yaml, .sh етс
... на json конфигах живет, например, Transmission (torrent клиент)
Мало данных?
Some Datasets Available on the Web - 398 больших наборов данных
Что-нить другое?
Структура ноды key-value хранилища
Полезность простой key-value базы
Масштабирование (sharding) key-value базы
Memcached
Consistent Hashing
Надежность - master/slave replication
"Кусочки" технологий для следующего шага