Базы данных: введение, часть седьмая
Илья Тетерин
2011-11-02
(use arrow keys or PgUp/PgDown to move slides)
Илья Тетерин
2011-11-02
(use arrow keys or PgUp/PgDown to move slides)
поисковая система своими руками
обратный (инвертированный индекс)
Lucene
HDFS
Задача: есть коллекция текстовых документов
Хочу искать по разным словам в них
Что-то типа Google или Яндекса ...
Папа, подари мне Яндекс - кратко, по русски, "сказка". Самый доходчивый документ для входа в мир поисковика :) - морфология, как искать, эмуляция через SQL etc.
Меня через эту статью "вводили", когда я пришел в Яндекс и _ничего_ не понимал.
* получить документы
* подготовить данные
* сделать базу документов
* придумать как искать по ним
* сделать обработку запросов пользователя
* отдать документы
В случае web коллекция велика и связана ссылками.
Пишем робота (web-паук / кравлер / crawler), который:
- скачивает страницу
- сохраняет страницу для обработки
- получает из нее ссылки на другие страниц
- идет за теми страницами ... и так по кругу
В случае локальной сети или предприятия - коллекцию могут нам выдать сразу
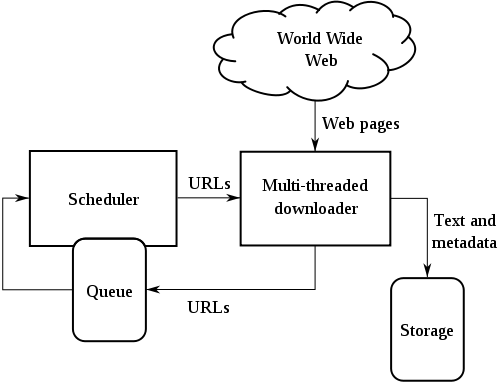
веб-граф, метаинформация, архив документов
Цитата из Архитектура поискового кластер Яндекса Den Raskovalov: 10^12 урлов ( миллион миллионов ) / 10^10 документов ( 10 тысяч миллионов ).
btw: РИА Новости 23.09.2011: Количество пользователей Facebook превысило 800 миллионов
Как хранить архив? Да хоть в haystack - как byte streams, причем вместо уменьшенных thumbnails можно хранить "сниппеты". Доступ по id документа и типу "тела".

Ответ:инвертированный индекс
Яндекс рекомендует:


Introduction to Information Retrieval, Cambridge University Press. 2008. курс лекций, по английски в свободном доступе
Введение в информационный поиск - перевод на русский, вычитанный в Яндексе. Ссылка на ozon.ru.
Как работают поисковые системы Илья Сегалович, Яндекс
Входящий документ разбиваем на токены (слова)
Для каждого токена делаем список документов, в которых он встречается
Поиск:
* на входе слово "мармелад"
* ищем токен "мармелад" в нашем списке токенов
* берем с него список id документов
* вот наш ответ - см. список
Поиск мармелад и яблоко:
* аналогично, но два списка
* списки пересекаем (merge отсортированных последовательностей = o(n) )
7:мармелад - { 107; 200; 320 ... }
109:яблоко - { 68; 80; 107; 190; 202; 320 ...
мармелад и яблоко - { 107; 320 ... }
А как хранить такой индекс?
1. Словарь:
Количество слов - в Oxford English Dictionary - 600 000 слов ... но там нет фамилий, имен, городов етс. => миллионы токенов => указатель int 2^32 может быть мало
Само слово надо хранить - это еще 20? unicode символов
2. Постинг лист (внутри Яндекс - кишка :) ):
идентификатор токена, потом ссылки на документы
Количество документов - 10^10 => указатель long 2^64
Примеры из книги на основе коллекции Reuters-RTV1.
Словарь токенов как массив фиксированной длины - мнооого памяти, не понятно, сколько памяти на токен (wiki: самое длинное слово: энтерогематогепатогематопульмоэнтерального)
Зато бинарный поиск - быстро, за o(ln n)
Изначально размер посчитан как 400 000 токенов * ( 20 + 4 + 4 ) = 11.2 Мбайт ( 4 byte = 2^32 = 4 Гбайт)
А если токены сложить в одну сплошную строку, а в массиве держать указатели на строку? Указатель на следующий токен == конец предыдущего токена?
{мармеладяблокояблоневыйяблочный} { 7:1, 109:9 ... }
Размер падает до 400 000 * ( 4 + 4 + 3 + 8 ) = 7.6 Мбайт (частота, указатель на постинг, ссылка на токен в строке, средняя длина токена)
А что если хранить блоками по 4 токена? (экономим указатели 4 бай) Заменим ссылку на токен на ссылку на блок, а в блоке последовательный перебор: {8мармелад6яблоко9яблоневый8яблочный} { 7:1, 109:X, 120:X, 130:28, ... } - поджали до 7.1 Мбайта
"Фронтально" пакуем - начала слов повторяются, заменяем повторы на #, а * - отрезает повторяющуюся часть от неповторимой в первом слове: {8мармелад6ябло*ко5#невый4#чный} - получим 5.9 Мбайт.
Много длинных последовательностей чисел... причем большой разрядности - 2^64
А если вместо абсолютной ссылки на документ держать относительную ?
109:яблоко -
{ 68; 80; 107; 190; 202; 320 ...
vs
{ 68; 12; 27; 83; 19; 118 ...
Токены по разному встречаются в документах - некоторые в каждом первом (the, is, а, и, но), некоторые очень очень редко - т.е. напрямую размер указателя все равно будет того же порядка - 2^64
Ответ: побитовое кодировние - коды разной длины для разных смещений - интересно и детально в книге
Исходная коллекция: - 800 000 документов
- 3.6 Гбайт данных (xml/html/текст)
- 960 Мбайт чистого текста
- 400 000 токенов
- словарь из 11.2 Мбайт - 5.9 Мбайт
- постинги - из 400 Мбайт в 101 Мбайт
Из 4 Гбайт разрозненных данных получили хранилище, по которому можно искать ... и оно полностью влезает в небольшую память (128Мбайт)
Для работы поисковой системы нужна своеобразная база - инвертированный индекс.
Для понимания характеристик - надо знать как оно устроено.
Будет понятно сколько нужно памяти, какой скорости ожидать етс.
Всегда компромиссы: в словаре o(ln n) при прямом дереве vs o(ln(n/4)) + o(4) при блоках по 4 токена
Сложно ... и интересно
Если "своё" - понимаешь и тюнишь, если чужое, то пользуешь и надеешься ...
Готовая, общедоступная библиотека полнотекстового поиска на Java
http://lucene.apache.org/java/docs/index.html
Используется: в 200+ проектах (PoweredBy)
... включая Twitter
Для меня: это _внешний_ индекс, позволяющий искать документы
Документы могут храниться внутри Lucene, но при больших объемах снаружи
Алгоритм работы:
* кладем документ в хранилище (haystack? :))
* отдаем документ в Lucene на индексацию
NB: у нас два процесса -> распределенное хранение -> "mind the CAP"

Для хороших результатов - нужен будет свой стеммер для русского языка
Стеммер - обрезальщик слов до корневой формы (например яблочный/яблочная -> яблочн).
Используется когда поиск не должен различать окончания
Запуск примера:
wget http://repo1.maven.org/maven2/org/apache
/lucene/lucene-core/3.4.0/lucene-core-3.4.0.jar
wget http://www.lucenetutorial.com/code/HelloLucene.java
javac -classpath .:lucene-core-3.4.0.jar HelloLucene.java
java -classpath .:lucene-core-3.4.0.jar HelloLucene
Результаты: Found 2 hits. 1. Lucene in Action 2. Lucene for Dummies
68 строк включая все импорты ...
Directory index = new RAMDirectory();
IndexWriterConfig config =
new IndexWriterConfig(Version.LUCENE_34, analyzer);
IndexWriter w = new IndexWriter(index, config);
addDoc(w, "Lucene in Action");
addDoc(w, "Lucene for Dummies");
addDoc(w, "Managing Gigabytes");
addDoc(w, "The Art of Computer Science");
w.close();
// addDoc() takes a string and adds it to the index:
private static void addDoc(IndexWriter w,
String value) throws IOException {
Document doc = new Document();
doc.add(new Field("title",
value, Field.Store.YES, Field.Index.ANALYZED));
w.addDocument(doc);
} }
String querystr = args.length > 0 ? args[0] : "lucene";
Query q = new QueryParser(Version.LUCENE_34, "title", analyzer)
.parse(querystr);
int hitsPerPage = 10;
IndexSearcher searcher = new IndexSearcher(index, true);
TopScoreDocCollector collector =
TopScoreDocCollector.create(hitsPerPage, true);
searcher.search(q, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs;
System.out.println("Found " + hits.length + " hits.");
for(int i=0;i<hits.length;++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("title"));
}
Работал в Excite, Apple, Xerox PARC, Yahoo, Cloudera...
Автор open-source проектов:
Lucene - библиотека полнотекстового поиска
Nutch - поисковый сервер, включающий кравлер и http сервер для результатов
Hadoop - набор технологий для MapReduce вычислений
July 2009 - выбран в совет директоров Apache Software Foundation, September 2010 - предстедатель совета директоров.
Патенты - 9 штук с 1991-по 1996 года в области поисковых технологий.
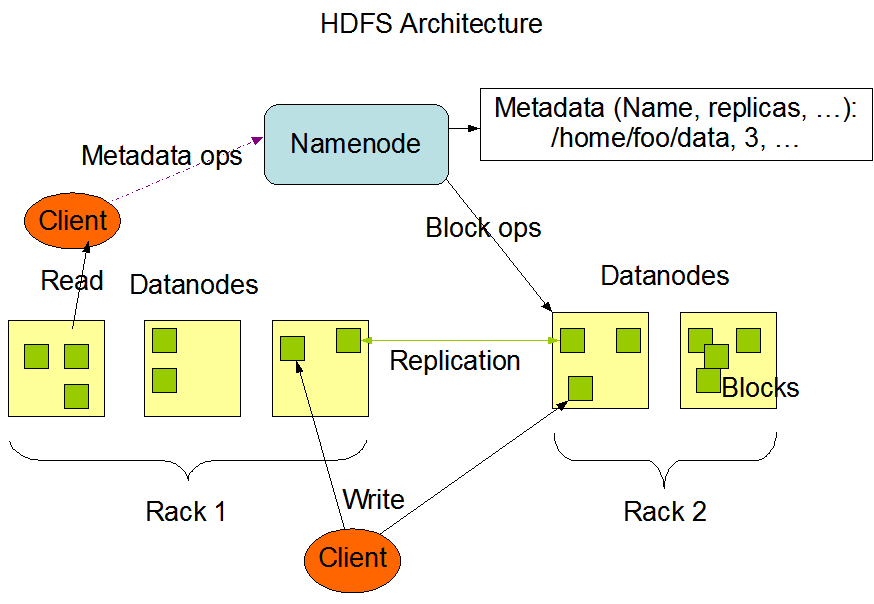
Single point of failure
Хранит информацию имя файла - список блоков - адреса блоков в кластере
Snapshot, read ahead log (EditLog) etc
Размер кластера, вернее количество файлов - это сколько мета-информации выдержит NameNode
Просто хранит понумерованные блоки по 64Mb
Блоки складываются в каталоги, с оптимальной нарезкой на подкаталоги, дабы не было 10к файлов в каталоге
Без метаинформации - блоки лишены смысла = мусор
Если на DataNode количество свободного места меньше порога - может быть принято решение о "миграции" блока на более свободную машину.
С обновлением информации в NameNode
Hadoop: The Definitive Guide, глава 4 - Hadoop I/O
Hadoop I/O: Sequence, Map, Set, Array, BloomMap Files
Split компрессия - у нас файл на 1Гб, блоки по 64Мб. Если можем split, то берем 10-ый блок и сразу с ним работаем. Если не поддерживается split - придется брать блоки с 1-го и последовательно распаковывать до нужного.
Можно свою сериализацию - хоть Thrift
последовательность ключ-значение
writer.put(key, value);
произвольный порядок
чтение - full scan при помощи next()
или sync(position) - система встанет в заданную позицию и от нее будет искать точки синхронизации
Header: 4 bytes: SEQ + byte версии Text - Key class name Text - Value class name Boolean - is compressed Boolean - is block compressed 16 bytes - sync метка (генерится на каждый файл своя) Record: int - key length + value length int - key length bytes[] key bytes[] value Block: int - колво записей в блоке int - длина ключей bytes[] - ключи int - длина блока значений bytes[] - значения Sync: (* sync ставится раз в Н записей (1% от данных, не более)) 16 bytes
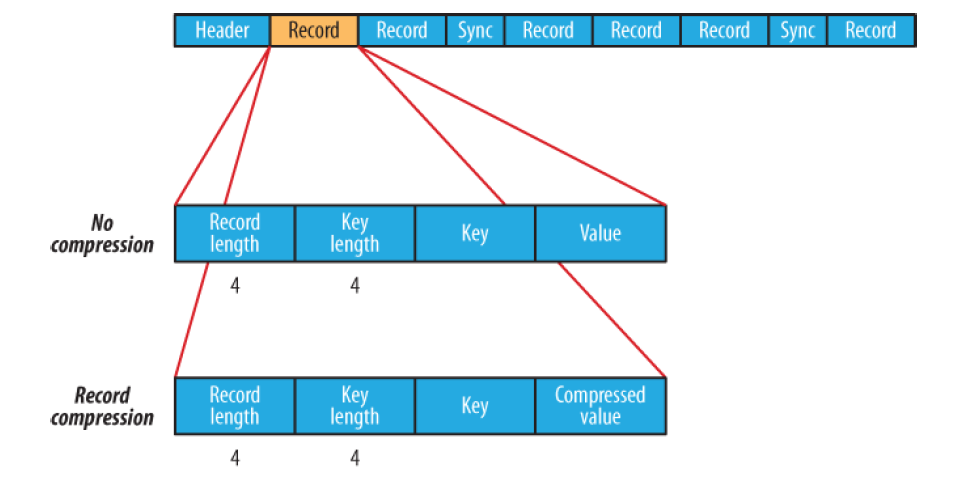
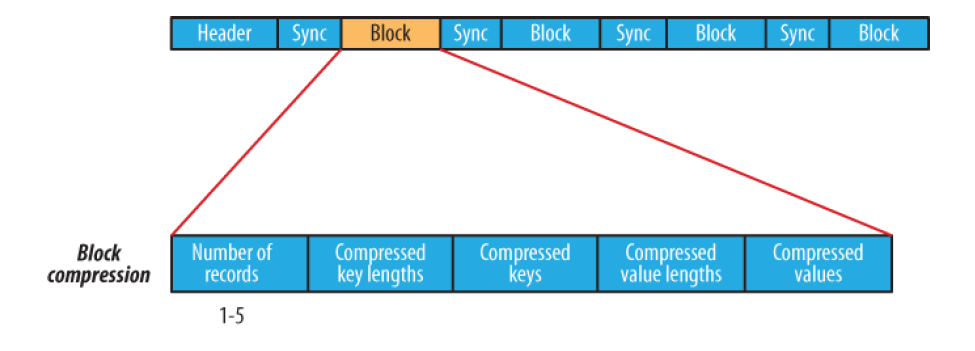
Взято из книги Hadoop: The Definitive Guide
Данные должны быть отсортированы по возрастанию ключа
Рядом с файлом данных - новый файл индекса
Можно lookup (подглядывать) по ключу
По умолчанию - только 128-ой ключ выкладывается в index файл - нельзя даже посчитать колво ключей
Если индекс файл очень большой - при работе можно брать только каждый 2-ой (256 записей) или 4-ый (1024 записи) ключ из индекса